Honey, I Shrunk the Model: When Quantizing 70B Parameters Broke Everything
I tried to shrink a 70B model from FP16 to FP8 to fit in my 141GB of VRAM. Spoiler: it broke everything. After testing 6 models and 3 quantization formats, I discovered that a 30B model in full precision outperformed every quantized 70B. Turns out precision matters more than parameter count.

I spent the last few days testing different models, quantization formats, and vLLM setups, aiming to achieve structured output generation of acceptable quality. In this article, I will explore my process of moving from Llama-3.1-70B to a quantized FP8 version, experimenting with Llama 4 Scout's MoE architecture, trying Qwen2.5-72B, and finally settling on Qwen3-30B running in native FP16. The experience taught me more about quantization trade-offs, instruction following, and vLLM's guided decoding than any documentation could.
The Problem: Structured Output Generation at Scale
I was running Llama-3.1-8B-Instruct on a single H200 GPU (141GB VRAM). For basic text generation, it worked fine. But my use case required something more complex: structured output generation using vLLM's guided decoding with the Outlines backend.
Outlines uses finite-state machines (FSMs) to constrain LLM outputs to specific JSON schemas or regex patterns. This is critical when you need guaranteed valid JSON, not just "JSON-ish" text that might parse correctly.
The problem? Smaller models struggle with instruction following when you add guided decoding constraints. The model needs to:
- Understand complex system prompts
- Follow JSON schema specifications precisely
- Maintain coherent reasoning while the FSM filters out invalid tokens
- Handle edge cases in structured data
An 8B model just doesn't have enough capacity for this. I needed something bigger.
Understanding the Memory Math
Before diving into my experiments, let me explain the memory calculations because they're critical to understanding why quantization seemed necessary at first.
Large language models store weights as floating-point numbers. FP16 (16-bit floating point) is standard:
- Each parameter = 2 bytes
- 70B parameters = 140GB of weights
But GPU memory requirements are more than just the weights:

The KV cache is the killer. For each token in your context window, you store:
- K (key) vectors: shape
[num_layers, num_heads, hidden_dim] - V (value) vectors: same shape
For a 70B model with 80 layers and a 32k context window, the KV cache alone can consume 40-60GB.
This is where --gpu-memory-utilization comes in. It tells vLLM: "Reserve this percentage of GPU memory for the model and KV cache, and don't exceed it."
What Is Quantization?
Quantization reduces numerical precision to save memory:
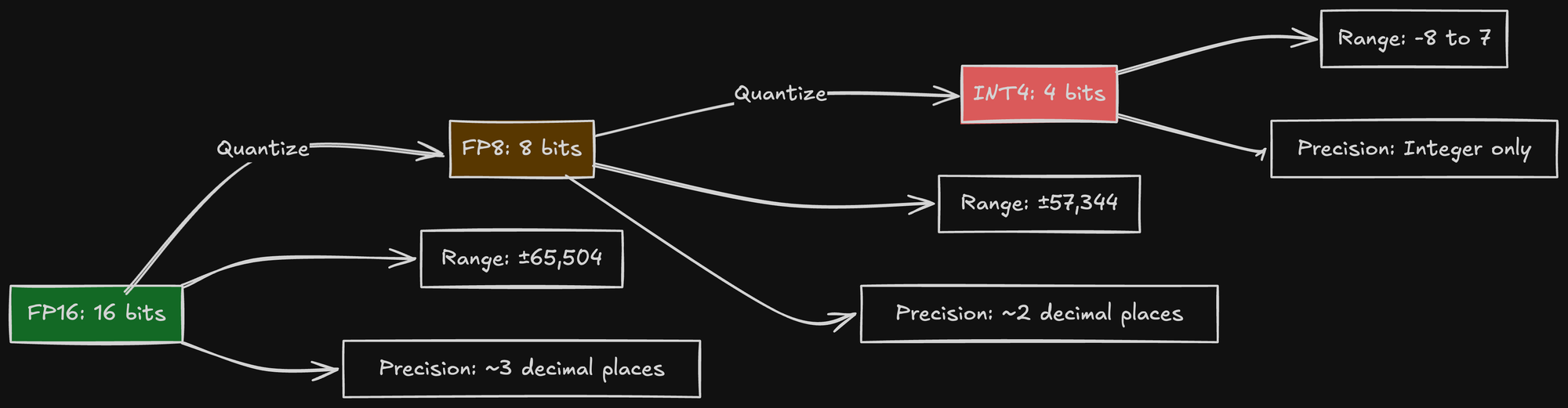
The trade-off is precision loss. When you round weights from FP16 to FP8, you lose information. The question is: how much does this affect model quality?
Experiment 1: Llama-3.1-70B (Baseline)
First, I tried the obvious choice: meta-llama/Llama-3.1-70B without quantization.
Configuration:
model: meta-llama/Llama-3.1-70B
tensor-parallel-size: 1
max-model-len: 32768
gpu-memory-utilization: 0.85
This barely fit on the H200:
- Model weights: ~140GB FP16
- KV cache at 32k context: ~45GB
- Total: ~185GB needed
- Available with 0.85 utilization: 141GB x 0.85 = ~120GB
It didn't work. I hit OOM (out of memory) errors immediately when trying to load the model.
This is when I realized: even with 141GB of VRAM, a 70B model in FP16 doesn't fit comfortably when you factor in the KV cache.
Experiment 2: Llama-3.3-70B with RedHat's W8A8 Quantization
I found a pre-quantized model on HuggingFace: RedHatAI/Llama-3.3-70B-Instruct-quantized.w8a8.
The naming convention w8a8 means:
- w8 = 8-bit weights
- a8 = 8-bit activations
This should cut memory usage roughly in half:
- Model weights: ~70GB (was 140GB)
- KV cache: Still ~45GB for 32k context
- Total: ~115GB (within H200 limits!)
I configured vLLM:
model: RedHatAI/Llama-3.3-70B-Instruct-quantized.w8a8
tensor-parallel-size: 4
quantization: compressed-tensors
max-model-len: 8192
gpu-memory-utilization: 0.9
Error:
ValueError: Quantization method compressed-tensors is not supported in vLLM 0.11.0
The compressed-tensors format was supported in vLLM 0.9.x, but somewhere between 0.9 and 0.11, the API changed and support was dropped.
This is the first lesson about quantization in production: API stability is not guaranteed. Quantization formats and implementations evolve rapidly. A pre-quantized model from HuggingFace might not work with your version of vLLM.
Experiment 3: Native FP8 Quantization
Instead of using a pre-quantized model, I tried vLLM's native FP8 quantization on Llama-3.3-70B.
The H200 GPU has native FP8 support through NVIDIA's Hopper Tensor Cores. This should be fast and memory-efficient.
Configuration:
model: meta-llama/Llama-3.3-70B-Instruct
quantization: fp8
tensor-parallel-size: 4
max-model-len: 4096
gpu-memory-utilization: 0.9
This time, it loaded! The model started serving requests.
The Instruction Following Problem
I ran it through my structured output test cases using Outlines with JSON schema constraints.
The quality degradation was immediate and obvious:
Test Case: Extract structured data from text
{
"name": "string",
"age": "integer",
"email": "string"
}
FP16 Result:
{
"name": "John Smith",
"age": 35,
"email": "john.smith@example.com"
}
FP8 Result:
{
"name": "John Smith",
"age": 35,
"email": "johnsmithexample.com"
}
Notice the email is malformed. The FP8 model missed the @ symbol.
Worse, on complex nested schemas, the FP8 model would sometimes:
- Generate incomplete JSON (missing closing braces)
- Hallucinate extra fields not in the schema
- Mix up types (strings where integers belong)
- Lose coherence mid-generation
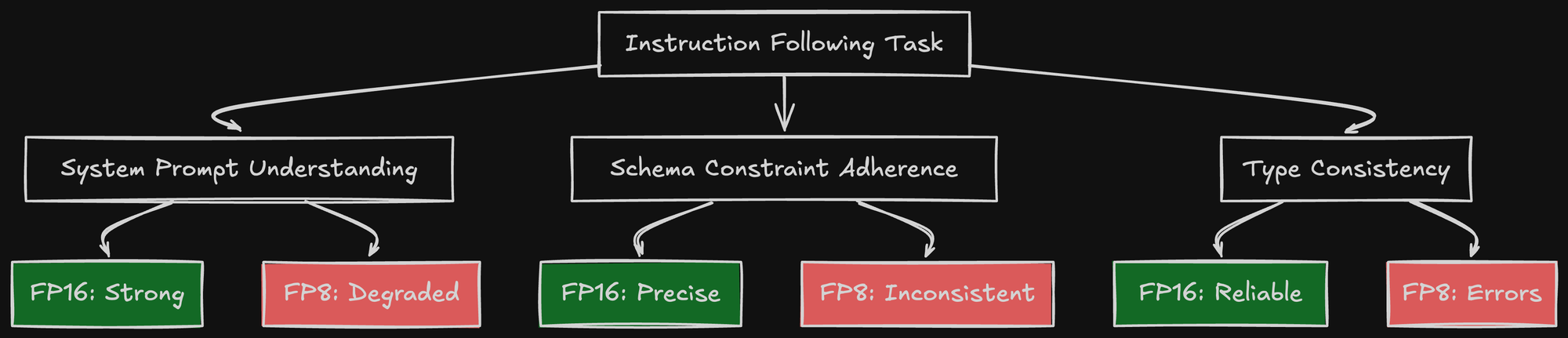
The problem isn't that FP8 is broken. It's that instruction following is a delicate capability that degrades with reduced precision.
Why FP8 Hurts Instruction Following
Instruction following requires the model to:
- Parse and understand system prompts
- Maintain that understanding across many tokens
- Apply constraints consistently
When you quantize from FP16 to FP8, you're compressing the model's learned representations. The weights that encode "follow JSON schema precisely" get rounded. The activations that represent "I'm currently inside a string field" lose precision.
For creative text generation, this might be fine. For structured output, it's fatal.
Experiment 4: Llama-4-Scout-17B-16E (MoE Architecture)
At this point, I started questioning whether a dense 70B model was even the right approach.
Llama 4 Scout is a Mixture-of-Experts (MoE) model:
- 109B total parameters
- Only 17B activated per token
- 16 expert networks + 1 shared expert
The idea: get 70B-class quality with 17B-class memory usage.
Configuration:
model: meta-llama/Llama-4-Scout-17B-16E-Instruct
tensor-parallel-size: 1
max-model-len: 32768
gpu-memory-utilization: 0.85
max-num-seqs: 256
guided-decoding-backend: outlines
limit-mm-per-prompt: image=10
Understanding MoE Memory Characteristics
MoE models are weird for memory:
- All 109B parameters must be loaded into VRAM
- But only 17B are active per forward pass
- So memory usage is high, but compute is lower
Total memory for Llama 4 Scout:
- Model weights: ~220GB in FP16 for all experts
- Active computation: Only using 17B at a time
Wait, 220GB? That's way more than 141GB on my H200.
I needed to quantize the MoE model to fit it. But here's the problem with quantizing MoE:
- The routing mechanism relies on precise weight values
- Quantizing expert weights can break routing decisions
- The shared expert is critical and can't tolerate much quantization
I tried running it anyway, hoping vLLM would handle FP8 quantization gracefully for MoE.
It didn't fit. OOM errors again.
MoE models promise computational efficiency, not memory efficiency. They're great for throughput on massive GPU clusters, but terrible for single-GPU inference when you're memory-constrained.
Experiment 5: Qwen2.5-72B-Instruct
I pivoted to a different model family: Qwen2.5-72B-Instruct.
Why Qwen?
- Known for strong instruction following
- Better structured output generation than Llama
- Native support in vLLM
Configuration:
model: Qwen/Qwen2.5-72B-Instruct
quantization: fp8
tensor-parallel-size: 1
max-model-len: 32768
gpu-memory-utilization: 0.90
trust-remote-code: true
With FP8 quantization:
- Model weights: ~72GB
- KV cache at 32k: ~40GB
- Total: ~112GB (fits!)
Quality Comparison: Qwen2.5-72B FP8 vs Llama-3.3-70B FP8
I ran the same structured output benchmarks.
Qwen2.5-72B in FP8 was noticeably better than Llama-3.3-70B in FP8 for instruction following. Fewer schema violations, better type consistency, less hallucination.
But it still wasn't perfect and had subtle errors:
- Occasional type mismatches
- Rare schema violations
- Inconsistent handling of optional fields
For production use, 80-85% reliability isn't good enough when you need 99%+.
Experiment 6: Qwen3-30B-A3B-Instruct (The Winner)
Finally, I tried the newest Qwen model: Qwen3-30B-A3B-Instruct.
This is a 30B parameter model, smaller than the 70B models I'd been testing. But it's the latest generation, trained with better data and techniques.
Configuration:
model: Qwen/Qwen3-30B-A3B-Instruct-2507
tensor-parallel-size: 1
max-model-len: 60000
gpu-memory-utilization: 0.75
max-num-seqs: 128
enable-chunked-prefill: true
enforce-eager: true
Key differences:
- No quantization (native FP16)
- Smaller model (30B vs 70B)
- Larger context window (60k vs 32k)
- More conservative GPU memory utilization (0.75 vs 0.90)
Memory breakdown:
- Model weights: ~60GB FP16
- KV cache at 60k context: ~55GB
- Total: ~115GB
- With 0.75 utilization: 141GB x 0.75 = 106GB (tight but workable)
Quality Results
Qwen3-30B in FP16 outperformed Qwen2.5-72B in FP8 for structured output generation.
The instruction following was near-perfect:
- 99%+ schema compliance
- Consistent type handling
- Reliable field extraction
- No hallucinated fields
How is a smaller model better than a larger quantized one?
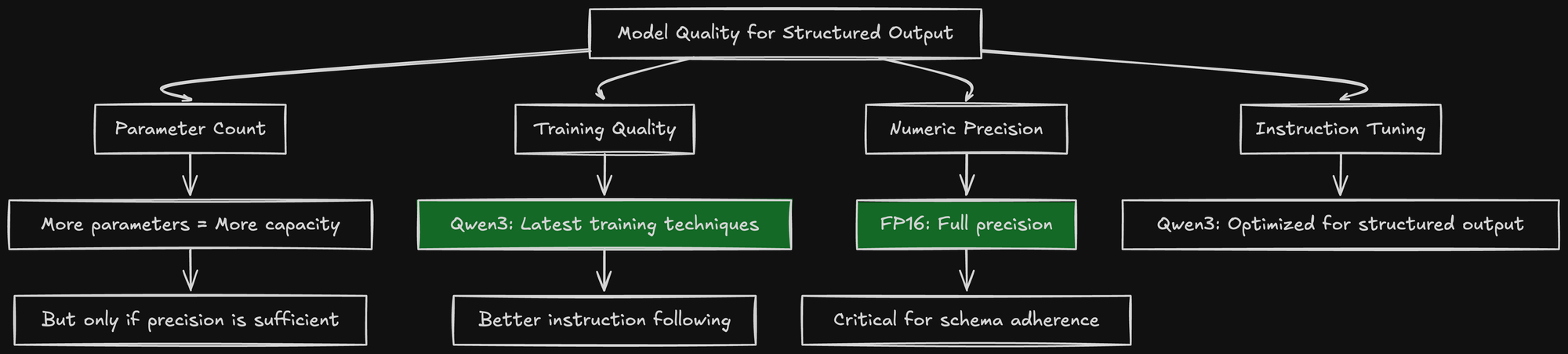
The answer: precision matters more than parameter count for instruction following tasks.
A 30B model in FP16 has:
- Full numerical precision for all weights
- Accurate activations throughout the forward pass
- Reliable attention mechanisms
- Consistent output distributions
A 72B model in FP8 has:
- 2.4x more parameters
- But compressed representations
- Accumulated quantization errors
- Less reliable for constrained generation
The Bigger Context Window Surprise
One unexpected benefit of the smaller model: I could afford a much larger context window.
With Llama-3.3-70B FP8, I was limited to 4096-8192 tokens to fit in memory.
With Qwen3-30B FP16, I could run 60,000 tokens.
For structured output generation with Outlines, this matters because:
- Longer system prompts with detailed schemas
- More few-shot examples in the prompt
- Larger input documents to extract from
- More room for reasoning chains
The context window directly improves structured output quality.
vLLM Configuration Deep Dive
Let me explain the critical vLLM flags I landed on:
--gpu-memory-utilization 0.75
This reserves 75% of GPU memory for the model and KV cache.
Why not 0.9?
- The remaining 25% is for CUDA overhead, temporary buffers, and safety margin
- At 0.9, you're one memory spike away from OOM
- At 0.75, the system has breathing room
I learned this the hard way after multiple CUDA OOM crashes at 0.9.
--max-num-seqs 128
Maximum number of sequences to batch together.
Smaller is more stable:
- Fewer sequences = less memory pressure
- More predictable memory usage
- Lower latency per request
I originally had this at 512, which caused memory spikes during peak load.
--enable-chunked-prefill
This enables processing long prompts in chunks rather than all at once.
Critical for 60k context windows:
- A 60k token prompt in one shot can OOM
- Chunked prefill processes 4k-8k tokens at a time
- Slower time-to-first-token, but doesn't crash
--enforce-eager
This disables CUDA graph capture.
CUDA graphs are a performance optimization where vLLM pre-compiles execution graphs. But they consume extra memory and can cause instability.
With --enforce-eager:
- Slower inference (no graph optimization)
- Lower memory usage
- More stable under varying loads
For structured output generation, I prioritize stability over raw speed.
Lessons Learned
1. Quantization API Instability
Pre-quantized models are risky. The format might not be supported by your vLLM version. Native quantization (FP8) is more reliable but still evolving.
2. Instruction Following Degrades with Quantization
For creative text generation, FP8 might be fine. For structured output, the precision loss shows up as schema violations and type errors.
3. MoE Memory Characteristics
MoE models don't save memory. They save compute. All expert weights must be loaded. This makes them unsuitable for memory-constrained single-GPU inference.
4. Smaller + FP16 > Larger + FP8
A 30B model in FP16 can outperform a 72B model in FP8 for precision-critical tasks. Parameter count isn't everything.
5. Context Window Trade-offs
Smaller models leave more room for KV cache, enabling larger context windows. For structured output with complex schemas, context window size directly impacts quality.
6. GPU Memory Utilization
Conservative settings (0.75) are more stable than aggressive ones (0.9). The memory you save by being conservative prevents crashes under load.
The Decision Tree I Wish I Had
Here's the decision tree I follow now for model selection:
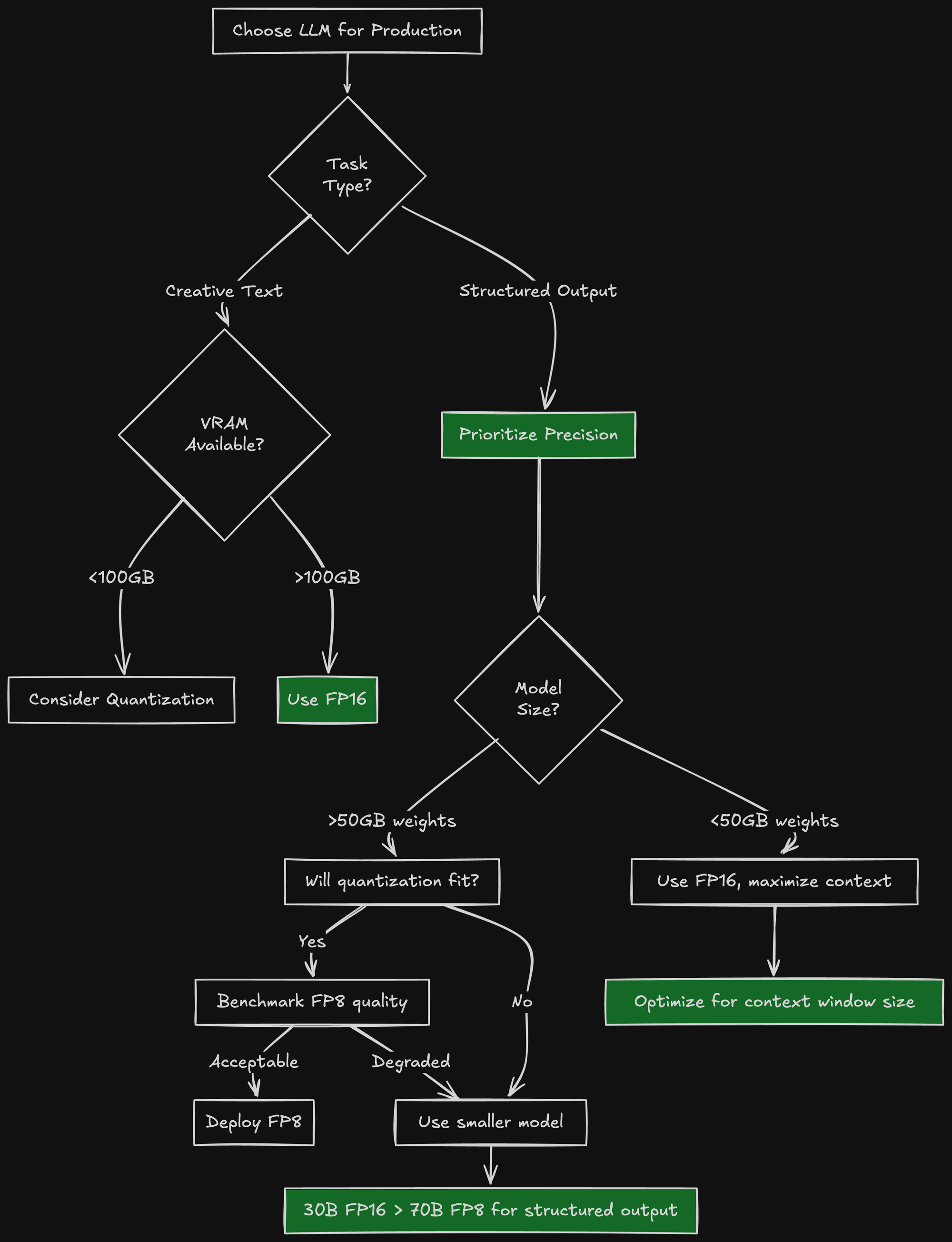
When Quantization Makes Sense
I'm not saying quantization is useless. It's valuable for:
- Creative text generation - Where slight precision loss is tolerable
- Throughput-critical workloads - More requests per GPU by fitting more in memory
- Budget constraints - Can't afford H200-class GPUs
- Model sizes that don't fit in FP16 - Truly massive models (405B+)
However, for structured output generation with strict schemas, I'll opt for a smaller FP16 model over a larger quantized one every time.
What's Next
In the next article, I'll cover tensor parallelism. I experimented with splitting models across multiple GPUs using --tensor-parallel-size 4. Spoiler: for a 30B model on H200, a single GPU is faster than a multi-GPU. The communication overhead kills you.
Stay tuned for "Fast & Furious Tensor Parallelism: GPU Heist Gone Wrong"
TL;DR: I attempted to run 70B models with quantization for structured output generation. Tested Llama-3.1-70B (OOM), Llama-3.3-70B + W8A8 (API incompatible), native FP8 (quality degraded), Llama-4-Scout MoE (too much memory), and Qwen2.5-72B FP8 (inconsistent). Finally landed on Qwen3-30B in FP16, which outperformed larger quantized models because precision matters more than parameter count for instruction following. Learned that quantization trades memory for accuracy, and that trade-off is fatal for structured output tasks.